说到做到,马斯克承诺的开源版大模型 Grok 终于来了!
今天凌晨,马斯克旗下大模型公司 xAI 宣布正式开源 3140 亿参数的混合专家(MoE)模型「Grok-1」,以及该模型的权重和网络架构。
这也使得Grok-1成为当前参数量最大的开源大语言模型。

封面图根据 Grok 提示使用 Midjourney 生成的:神经网络的 3D 插图,具有透明节点和发光连接,以不同粗细和颜色的连接线展示不同的权重。
这个时候,马斯克当然不会忘了嘲讽 OpenAI 一番,「我们想了解更多 OpenAI 的开放部分」。
回到模型本身,Grok-1 从头开始训练,并且没有针对任何特定应用(如对话)进行微调。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。
Grok-1 的模型细节包括如下:
基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;
3140 亿参数的 MoE 模型,在给定 token 上的激活权重为 25%;
2023 年 10 月,xAI 使用 JAX 库和 Rust 语言组成的自定义训练堆栈从头开始训练。
xAI 遵守 Apache 2.0 许可证来开源 Grok-1 的权重和架构。Apache 2.0 许可证允许用户自由地使用、修改和分发软件,无论是个人还是商业用途。项目发布短短四个小时,已经揽获 3.4k 星标,热度还在持续增加。
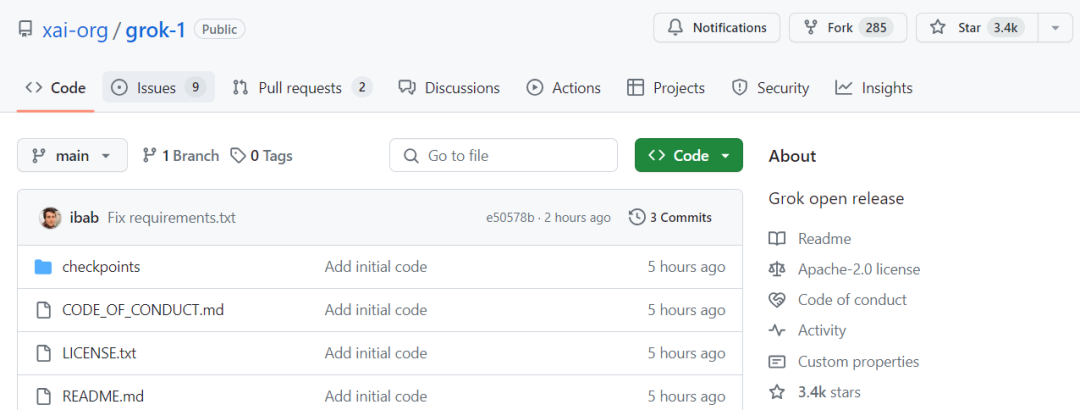
项目地址:https://github.com/xai-org/grok-1
该存储库包含用于加载和运行 Grok-1 开放权重模型的 JAX 示例代码。使用之前,用户需要确保先下载 checkpoint,并将 ckpt-0 目录放置在 checkpoint 中, 然后,运行下面代码进行测试:
pip install -r requirements.txt
python run.py
项目说明中明确强调,由于 Grok-1 是一个规模较大(314B 参数)的模型,因此需要有足够 GPU 内存的机器才能使用示例代码测试模型。此外,该存储库中 MoE 层的实现效率并不高,之所以选择该实现是为了避免需要自定义内核来验证模型的正确性。
用户可以使用 Torrent 客户端和这个磁力链接来下载权重文件:
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
看到这,有网友开始好奇 314B 参数的 Grok-1 到底需要怎样的配置才能运行。对此有人给出答案:可能需要一台拥有 628 GB GPU 内存的机器(每个参数 2 字节)。这么算下来,8xH100(每个 80GB)就可以了。
知名机器学习研究者、《Python 机器学习》畅销书作者 Sebastian Raschka 评价道:「Grok-1 比其他通常带有使用限制的开放权重模型更加开源,但是它的开源程度不如 Pythia、Bloom 和 OLMo,后者附带训练代码和可复现的数据集。」
DeepMind 研究工程师 Aleksa Gordié 则预测,Grok-1 的能力应该比 LLaMA-2 要强,但目前尚不清楚有多少数据受到了污染。另外,二者的参数量也不是一个量级。

如需购买OpenAI/ChatGPT 官方账号、API Key、GPT-4.0 Plus 订阅账号,以及 OpenKey 账号池等商品/服务,请点击链接:
https://shop.51buygpt.net/
牛爷爷团队致力于深耕ChatGPT AI生态圈,提供社区支持以及可靠的质量保证。