OpenAI展示创新文生视频模型Sora后,再次在全球范围内掀起了去年“ChatGPT”的盛况,点燃了文生视频赛道。
国内著名开源团队Colossal-AI(潞晨科技旗下)根据Sora技术报告、VideoGPT、扩散Transformers等资料,复现了Sora模型架构方案并将其开源——Open-Sora。
值得一提的是,Colossal-AI还将复现成本降低了46%,同时将模型训练输入序列长度扩充至819K patches。目前,Open-Sora在Github超过1200颗星。
开源地址:https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file
Sora算法复现
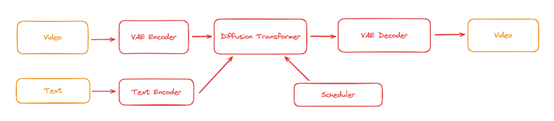
根据Sora技术报告展示来看,Sora使用了一个视频压缩网络将各种尺寸的视频压缩成一个隐空间(latent space)的时空块序列(a sequence of patial temporal patch),然后使用了Diffusion Transformer进行去噪,最后进行解码生成视频。
Open-Sora将Sora可能使用的训练pipeline归纳为下图。
目前Open-Sora已涵盖:
提供完整的Sora复现架构方案,包含从数据处理到训练推理全流程。
支持动态分辨率,训练时可直接训练任意分辨率的视频,无需进行缩放。
支持多种模型结构。由于Sora实际模型结构未知,Open-Sora实现了adaLN-zero、cross attention、in-context conditioning(token concat)等三种常见的多模态模型结构。
支持多种视频压缩方法。用户可自行选择使用原始视频、VQVAE(视频原生的模型)、SD-VAE(图像原生的模型)进行训练。
支持多种并行训练优化。包括结合Colossal-AI的AI大模型系统优化能力,及Ulysses和FastSeq的混合序列并行。
Open-Sora性能优化
不同于LLM的大模型、大激活,Sora类训练任务的特点是模型本体不大(如在10B以下),但是由于视频复杂性带来的序列长度特别长。
在此情况下,PyTorch数据并行已无法运行,而传统的模型并行、零冗余数据并行带来的收益有限。
因此,在支持AMP (FP16/BF16)、Flash Attention、Gradient checkpointing、ZeRO-DP等场景优化策略的基础上,Open-Sora进一步引入两种不同的序列并行方法实现,可以ZeRO一起使用实现混合并行:
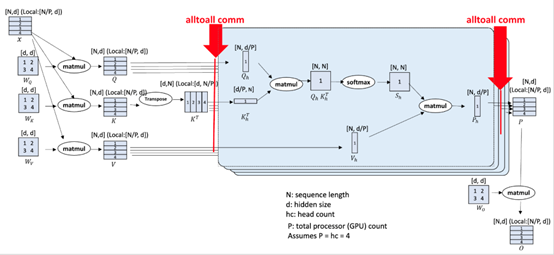
1.通用性较强的Ulysses,对小规模或长序列表现可能更好。
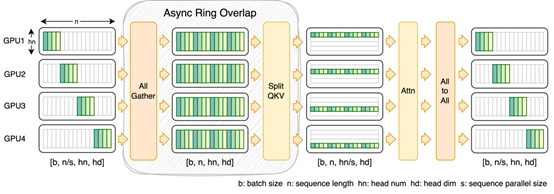
2.FastSeq能将qkv projection的计算和all-gather通信重叠,只需多占用一点内存就可更进一步提升训练效率。这两种序列并行方案都可以轻松与ZeRO2共同使用来实现混合并行。
以在单台H800 SXM 8*80GB GPU上使用DiT-XL/2模型的性能测试为例,在600K的序列长度时,Open-Sora的方案比基线方案有40%以上的性能提升和成本降低。
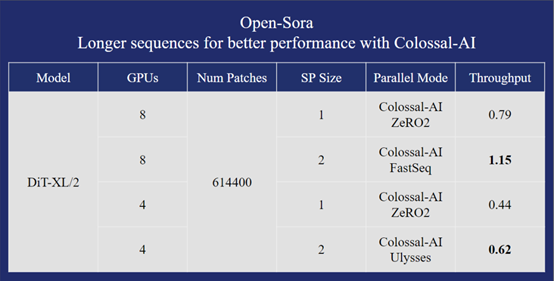
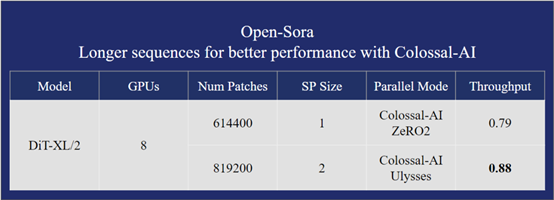
在保证更快训练速度的情况下,Open-Sora还能训练30%更长的序列,达到819K+。
Colossal-AI表示,未来会持续迭代、创新Open-Sora,希望借助开源的力量可以打造媲美Sora的产品,帮助影视、游戏开发、广告营销等领域实现降本增效。
如需购买OpenAI/ChatGPT 官方账号、API Key、GPT-4.0 Plus 订阅账号,以及 OpenKey 账号池等商品/服务,请点击链接:
https://shop.51buygpt.net/
牛爷爷团队致力于深耕ChatGPT AI生态圈,提供社区支持以及可靠的质量保证。